本文最后更新于:2025年2月22日 下午
开篇
问题概述
20220606 5G IoT 网关设备同时安装 K3S Server, 但是 POD 却无法访问互联网地址,查看 CoreDNS 日志提示如下:
1 2 3 4 ...
即 DNS 查询 forward 到了 8.8.8.8 这个 DNS 服务器,并且查询超时。
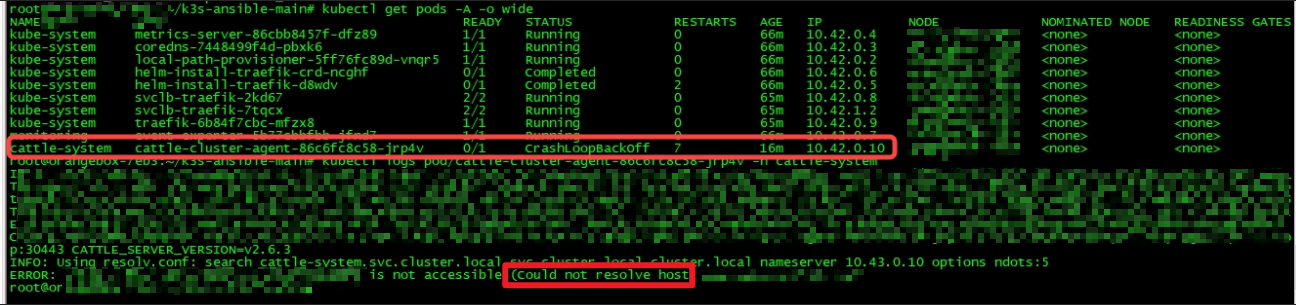
从而导致需要联网启动的 POD 无法正常启动,频繁 CrashLoopBackoff, 如下图:
但是通过 Node 直接访问,却是可以正常访问的,如下图:
环境信息
硬件:5G IoT 网关
网络:
互联网访问:5G 网卡:就是一个 usb 网卡,需要通过拨号程序启动,程序会调用系统的 dhcp/dnsmasq/resolvconf 等
内网访问:wlan 网卡
软件:K3S Server v1.21.7+k3s1, dnsmasq 等
分析
网络详细配置信息
一步一步检查分析:
看 /etc/resolv.conf, 发现配置是 127.0.0.1
netstat 查看 本地 53 端口确实在运行
这种情况一般都是本地启动了 DNS 服务器或 缓存,查看 dnsmasq 进程是否存在,确实存在
dnsmasq 用的 resolv.conf 配置是 /run/dnsmasq/resolv.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 $ cat /etc/resolv.conf# Generated by resolvconf $ netstat -anpl|grep 53 $ ps -ef|grep dnsmasq $ systemctl status dnsmasq.service $ cat /run/dnsmasq/resolv.conf# Generated by resolvconf
CoreDNS 分析
这里很奇怪,就是没发现哪儿有配置 DNS 8.8.8.8, 但是日志中却显示指向了这个 DNS:
1 2 [ERROR] plugin/errors: 2 update.traefik.io. A: read udp 10.42.0.3:38545->8.8.8.8:53: i/o timeout
先查看一下 CoreDNS 的配置:(K3S 的 CoreDNS 是通过 manifests 启动的,位于:/var/lib/rancher/k3s/server/manifests/coredns.yaml 下)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 apiVersion: v1 kind: ConfigMap metadata: name: coredns namespace: kube-system data: Corefile: | .:53 { errors health ready kubernetes cluster.local in-addr.arpa ip6.arpa { pods insecure fallthrough in-addr.arpa ip6.arpa } hosts /etc/coredns/NodeHosts { ttl 60 reload 15s fallthrough } prometheus :9153 forward . /etc/resolv.conf cache 30 loop reload loadbalance }
这里主要有 2 个配置需要关注:
forward . /etc/resolv.confloop
CoreDNS 问题常用分析流程
检查 DNS Pod 是否正常运行 - 结果:是的;
1 2 3 # kubectl -n kube-system get pods -l k8s-app=kube-dns
检查 DNS 服务是否存在正确的 cluster-ip - 结果:是的:
1 2 3 # kubectl -n kube-system get svc -l k8s-app=kube-dns
检查是否能解析域名:
1 2 3 4 5 $ kubectl run -it --rm --restart=Never busybox --image=busybox -- nslookup kubernetes.default
再试外部域名 - 结果:无法解析:
1 2 3 4 5 $ kubectl run -it --rm --restart=Never busybox --image=busybox -- nslookup www.baidu.com
检查 resolv.conf 中的 nameserver 配置 - 结果:确实是 8.8.8.8
1 2 3 $ kubectl run -i --restart=Never --rm test -${RANDOM} --image=ubuntu --overrides='{"kind":"Pod", "apiVersion":"v1", "spec": {"dnsPolicy":"Default"}}' -- sh -c 'cat /etc/resolv.conf'
综上:/etc/resolv.conf 被配置为 nameserver 8.8.8.8 导致了此次问题。nameserver 8.8.8.8, 所以怀疑是:Kubernetes、Kubelet、CoreDNS 或 CRI 层面有这样的机制:在 DNS 配置异常时,自动配置其为 nameserver 8.8.8.8。
那么,要解决问题,还是要找到 DNS 配置异常。
容器网络 DNS 服务
我这里暂时没有查到 Kubernetes、Kubelet、CoreDNS 或 CRI 的相关 DNS 的具体证据,K3S 的 CRI 是 containerd,但是我在 Docker 的官方文档 看到了这样的描述:
📚️ Reference:
这里猜测 Kubernetes、Kubelet、CoreDNS 或 CRI 可能也有类似的机制。
从这里分析可以知道,根因还是 DNS 配置问题,CoreDNS 配置是默认的,那么最大的可能就是 /etc/resolv.conf 配置为 nameserver 127.0.0.1 导致的此次问题。
根因分析
根因 : /etc/resolv.conf 配置为 nameserver 127.0.0.1 导致的此次问题。
CoreDNS 的官方文档明确说明了这种情况:
📚️ Reference:
loop | CoreDNS Docs Loop ... detected ... 时,这意味着检测插件 loop 在其中一个上游 DNS 服务器中检测到无限转发循环。这是一个致命错误,因为使用无限循环进行操作将消耗内存和 CPU,直到主机最终内存不足死亡。127.0.0.1、::1 或 127.0.0.53 等环回地址
这里可以看到,我们的 CoreDNS 配置包含:forward . /etc/resolv.conf, 且 Node 上的 /etc/resolv.conf 为 nameserver 127.0.0.1. 和上面提到的无限转发循环 的 致命错误 匹配。
转发环路通常由以下原因引起:
最常见的是,CoreDNS 将请求直接转发到自身。例如,通过环回地址,例如 ,或 127.0.0.1::1127.0.0.53
解决办法
📚️ Reference:
loop | CoreDNS Docs
kubelet 添加 --resolv-conf 直接指向 "真正" 的 resolv.conf, 一般是:/run/systemd/resolve/resolv.conf
禁用 Node 上的本地 DNS 缓存
quick dirty 办法:修改 Corefile, 把 forward . /etc/resolv.conf 替换为 forward . 8.8.8.8 等可以访问的 DNS 地址
针对上面的办法,我们逐一分析下:
✔️ 可行:kubelet 添加 --resolv-conf 直接指向 "真正" 的 resolv.conf: 如上文所述,我们的 "真正" 的 resolv.conf 为:/run/dnsmasq/resolv.conf
❌ 不可行:禁用 Node 上的本地 DNS 缓存,因为这是基于 5G IoT 网关的特殊情况,5G 网关程序机制就是如此,要用到 dnsmasq
❌ 不可行:dirty 的办法,并且 5G 网关获取到的 DNS 是不固定,随时变化的,所以我们也无法指定 forward . <固定的 DNS 地址>
综上,解决办法如下:--resolv-conf /run/dnsmasq/resolv.conf
添加后如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 [Unit] Description =Lightweight KubernetesDocumentation =https://k3s.ioWants =network-on line.targetAfter =network-on line.target[Install] WantedBy =multi-user.target[Service] Type =notifyEnvironmentFile =/etc/systemd/system/k3s.service.envKillMode =processDelegate =yes LimitNOFILE =1048576 LimitNPROC =infinityLimitCORE =infinityTasksMax =infinityTimeoutStartSec =0 Restart =alwaysRestartSec =5 sExecStartPre =-/sbin/modprobe br_netfilterExecStartPre =-/sbin/modprobe overlayExecStart =/usr/local/bin/k3s server --flannel-iface wlan0 --write-kubeconfig-mode "644" --disable-cloud-controller --resolv-conf /run/dnsmasq/resolv.conf
然后执行如下命令 reload 和 重启:
1 2 3 4 systemctl daemon-reload
即可恢复正常。
如果需要在安装时解决,解决办法如下:
使用 k3s-ansible 脚本,group_vars 额外再添加如下 --resolv-conf 参数:extra_server_args: '--resolv-conf /run/dnsmasq/resolv.conf'
使用 k3s 官方脚本:参考 K3s Server 配置参考 | Rancher 文档 , 添加参数:--resolv-conf /run/dnsmasq/resolv.conf 或使用环境变量:K3S_RESOLV_CONF=/run/dnsmasq/resolv.conf
🎉🎉🎉
📚️参考文档